
Becoming a better data scientist: use wrappers
Why using wrappers can help you ship code better and faster in data science.
Productionizing data science code
Data science projects today tend to use lots of open source libraries because they are an effective in producing prototypes.
After you build a prototype, the next question is: how do I productionize it?
As a data scientist, I want my code to be easy to productionize and start creating value as soon as possible. This means there are a few patterns I can use in my code to speed things up for everyone, including myself. Here’s one pattern that I’ve seen great success: use wrappers.
Why wrappers
One may ask: why do you want to wrap a library with your own function? Isn’t it doing the same thing? Looks like waste of time to me.
Short answer: no, it’s not a waste of time.
An example
Here’s an example. Let’s say I’m building a computer vision project and I need to load images. I have several libraries that I can use
Pillow:Image.open()opencv:cv2.imread()matplotlib:matplotlib.pyplot.imread()
Let’s say I decide to go with Pillow. A pattern that I saw in online tutorials is that the author would take a object coming from an external library and plug it straight into their code:
# model.py
from PIL import Image
def my_model_1(path):
image = Image.open(path)
# do something to image...
def my_model_2():
image = Image.open(path)
# do something to image...
This innocuous piece of code creates a problem: You are locked into Pillow’s implementation of loading image:
If I want to implement a new method for Image that’s not part of Pillow, I’m in trouble. I’ve seen people spending time debating on
* whether switching to another library, say `opencv` is better, or
* whether to override the native `PIL.Image` method by forking it into a company repo,
etc. None of them are as good as using a wrapper because of the downstream maintenance cost they incur.
If the class PIL.Image ended up being used in 100 places, then the switching cost to another library is a code change in 100 places. The risk of breaking production code is too high.
What I would do with wrapper
Let’s go back to the image reading example. Let’s examine how different those 3 libraries read images.
This is the image I’m going to use:

I want to read pixel (108, 223), which is the pink blush on the cat’s cheek. Here’s what the three libraries represent this single pixel as numpy arrays:
and they are all different 😱!!
# Pillow uses RGB format
pillow_array[108, 223, :]
>>> array([ 0, 53, 106], dtype=uint8)
# OpenCV uses BGR format
opencv_array[108, 223, :]
>>> array([106, 53, 0], dtype=uint8)
# Matplotlib is RGB scaled between 0 and 1
matplotlib_array[108, 223, :]
>>> array([0. , 0.20784314, 0.41568628], dtype=float32)
Imagine that you are an engineer and want to convert a data scientist’s code from using matplotlib to read images to using Pillow, how many places you would need to change and check that it’s not breaking the code?
This is only a single .png file. There are other image formats like .jpg, .webp and colorscales that make this problem even moer complicated in reality.
Making wrappers
This is where wrappers come in handy if I remembered to use it before I let an external library into my code.
For example, I can define my own class called MyImage that wraps around PIL.Image:
# utils.py
import numpy as np
from PIL import Image
class MyImage:
def __init__(self, data):
self.data = data
# ... however you want it
@classmethod
def read(cls, path):
with Image.open(path) as image:
return cls(data=np.asarray(image.convert('RGB')))
and in our original code:
from my_project.utils import MyImage
def my_model_1():
# ...
image = MyImage.read('something')
# do something to image...
def my_model_2():
# ...
image = MyImage.read('something')
# do something to image
that’s it. Now I can change the internals of MyImage, say an attribute .channel, to track whether it is BGR or RGB to feed into models in opencv.
This time, the Pillow library only has a single contact point with my code. If production requires using a different library, we only need to change and test a single place — the interface MyImage.
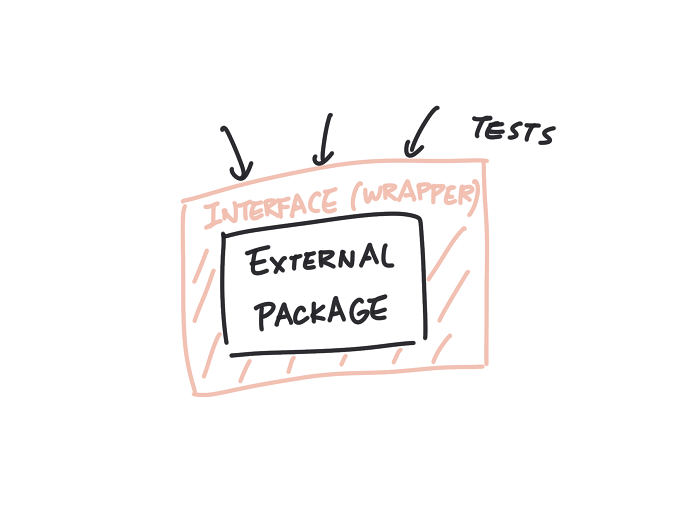
This also makes testing easy because the wrapper hid the complex PIL.Image object and only show the methods and attributes that we care about. Mocking MyImage is much easier than mocking PIL.Image.
Why is this better again?
Let me say again why this is a good idea:
- You only need to change one place if you want to replace a library
- It is easier to test because it is easier to mock.
In my experience, 1 saves a lot of time for project handoffs. For example,
- In deep learning libraries, the one group of data scientist uses
DataLoader()from PyTorch but another group usesDatasetin Tensorflow. - In JavaScript, the one team uses
axiosfor making API calls but another team wants to use.fetch().
Data I/O code tend to scatter all over the codebase and the large footprint makes it hard to factor if a new need arises. In other words, it is technical debt.
When not to wrap
What are some places that you may not want a wrapper, even if it is a third party library?
I think for common data formats, there is no need to make a wrapper for it.
For example,
numpy.arraypandas.DataFrame
are everywhere in a data science project. They are essential data formats for modules to communicate with each other. Wrapping around them cause more trouble than gain.
 This is fine
This is fine
Takeaways
When you write new code that uses a function or a class from an external library, think about what you actually need from it and write a wrapper around said function or class.
This makes change in the future easier and reduce technical debt for handoff between teams.
References
- Wrapping third party library is best practice
- Wrapper on Wikipedia
- Jupyter Notebook used in this post