
How to Install and Run PySpark in Jupyter Notebook on Windows
When I write PySpark code, I use Jupyter notebook to test my code before submitting a job on the cluster. In this post, I will show you how to install and run PySpark locally in Jupyter Notebook on Windows. I’ve tested this guide on a dozen Windows 7 and 10 PCs in different languages.
A. Items needed
-
Spark distribution from spark.apache.org
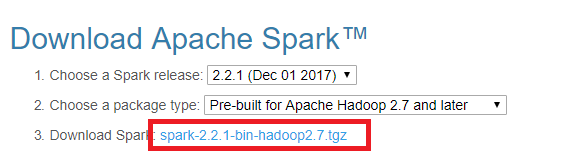
-
Python and Jupyter Notebook. You can get both by installing the Python 3.x version of Anaconda distribution.
-
winutils.exe— a Hadoop binary for Windows — from Steve Loughran’s GitHub repo. Go to the corresponding Hadoop version in the Spark distribution and findwinutils.exeunder /bin. For example, https://github.com/steveloughran/winutils/blob/master/hadoop-2.7.1/bin/winutils.exe .
-
The
findsparkPython module, which can be installed by runningpython -m pip install findsparkeither in Windows command prompt or Git bash if Python is installed in item 2. You can find command prompt by searchingcmdin the search box.
-
If you don’t have Java or your Java version is 7.x or less, download and install Java from Oracle. I recommend getting the latest JDK (current version 9.0.1).
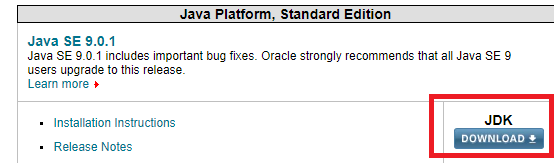
-
If you don’t know how to unpack a .tgz file on Windows, you can download and install 7-zip on Windows to unpack the .tgz file from Spark distribution in item 1 by right-clicking on the file icon and select
7-zip > Extract Here.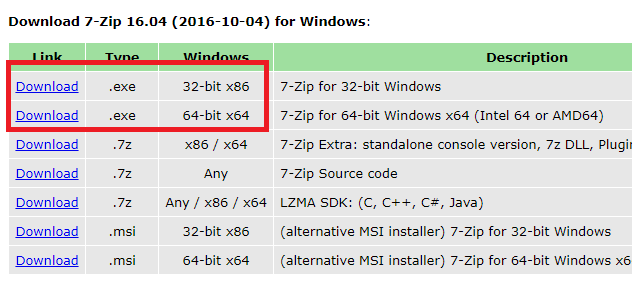
B. Installing PySpark
After getting all the items in section A, let’s set up PySpark.
-
Unpack the .tgz file. For example, I unpacked with 7zip from step A6 and put mine under
D:\spark\spark-2.2.1-bin-hadoop2.7
-
Move the
winutils.exedownloaded from step A3 to the\binfolder of Spark distribution. For example,D:\spark\spark-2.2.1-bin-hadoop2.7\bin\winutils.exe -
Add environment variables: the environment variables let Windows find where the files are when we start the PySpark kernel. You can find the environment variable settings by putting “environ…” in the search box.
The variables to add are, in my example,
Name Value SPARK_HOME D:\spark\spark-2.2.1-bin-hadoop2.7 HADOOP_HOME D:\spark\spark-2.2.1-bin-hadoop2.7 PYSPARK_DRIVER_PYTHON jupyter PYSPARK_DRIVER_PYTHON_OPTS notebook 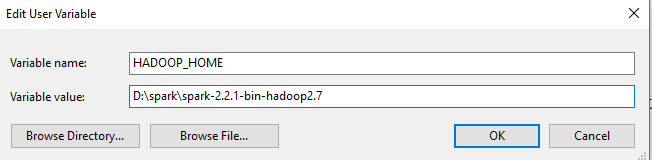
-
In the same environment variable settings window, look for the
PathorPATHvariable, click edit and addD:\spark\spark-2.2.1-bin-hadoop2.7\binto it. In Windows 7 you need to separate the values inPathwith a semicolon;between the values. -
(Optional, if see Java related error in step C) Find the installed Java JDK folder from step A5, for example,
D:\Program Files\Java\jdk1.8.0_121, and add the following environment variableName Value JAVA_HOME D:\Progra~1\Java\jdk1.8.0_121 If JDK is installed under
\Program Files (x86), then replace theProgra~1part byProgra~2instead. In my experience, this error only occurs in Windows 7, and I think it’s because Spark couldn’t parse the space in the folder name.Edit (1/23/19): You might also find Gerard’s comment helpful: http://disq.us/p/1z5qou4
C. Running PySpark in Jupyter Notebook
To run Jupyter notebook, open Windows command prompt or Git Bash and run jupyter notebook. If you use Anaconda Navigator to open Jupyter Notebook instead, you might see a Java gateway process exited before sending the driver its port number
error from PySpark in step C. Fall back to Windows cmd if it happens.
Once inside Jupyter notebook, open a Python 3 notebook
In the notebook, run the following code
import findspark
findspark.init()
import pyspark # only run after findspark.init()
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
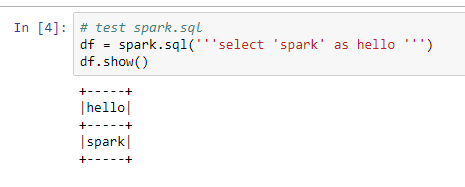
df = spark.sql('''select 'spark' as hello ''')
df.show()
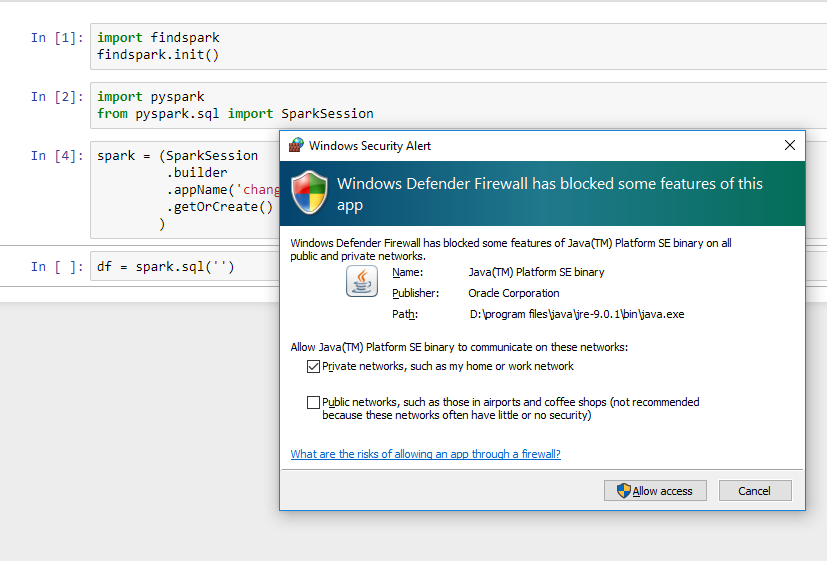
When you press run, it might trigger a Windows firewall pop-up. I pressed cancel on the pop-up as blocking the connection doesn’t affect PySpark.
If you see the following output, then you have installed PySpark on your Windows system!
Misc
- Update (10/30/19): Tip from Nathaniel Anderson in comments: you might want to install Java 8 and point JAVA_HOME to it if you are seeing this error: “Py4JJavaError: An error occurred…” StackOverflow Answer
Please leave a comment in the comments section or tweet me at @ChangLeeTW if you have any question.
Other PySpark posts from me (last updated 3/4/2018) —