
Agile in Data Science: Why My Scrum Doesn't Work?
Scrum is one of the most popular Agile framework. Data scientist from different teams, however, have been telling me that Scrum does not work for data science projects. Why is that?
In this post, I want to examine the two most common Agile frameworks: Scrum and Kanban, their fundamental differences, and how they apply to data science.
The idea behind Scrum
The key idea behind Scrum is timeboxing.
- https://www.scrum.org/resources/what-is-a-sprint-in-scrum
Scrum divides the project into sprints, or timeboxes, by defining the set of tasks that the team has to complete in a certain period of time. No additional task can be added within the sprint.
Sprints are designed to minimize external interruptions from stakeholders. Between sprints, the team reviews the previous sprint and plans for the next one. Therefore, once the sprint goal is set, no change happens without good reasons.
The reason behind the structure has to do with the nature of software development: it requires concentration. In my experience, letting people move the goalposts around in a project (scope creep), is a major source of frustration for everyone. But this leads to a question: when I say people move the goalposts around,
- how does the goalpost move?
In other words, if the scope of a project has to change, where does the change come from and how does it happen?
The difference between data science and software development
I was in Atlanta last November for a conference, DataSciCon. One hallway conversation in the event changed how I view data science projects since:
Last week in our discussion, @KirkDBorne said that the #1 quality for data scientists is "tolerance of ambiguity." It really sticks with me.
— Chang Hsin Lee (@ChangLeeTW) December 5, 2018
What does ambiguity mean?
Software development
I do not have much experience in building software. If I want to build a web app or a mobile app, however, I can ask my developer friends and they can help me come up with a solid spec for me to break into smaller tasks later.
In other words, I can write a spec to ship the first version of my app.
(PS. spec, or specification in software development, is a description of how the software should work and be developed.)
Once my first version goes out and user feedback comes back, I can then iterate on the design. A good spec will likely lead to a product.
But in data science, having a spec does not guarantee a product.
Data science
I see good software specs as Directions from Google Maps—there are many ways to get to the destination, but all of them are correct, we just pick one that has the lowest opportunity cost.
In data science, however, good spec, even if you can come up with one, does not guarantee the success.
Most of software development’s ambiguity come from known unknowns—I know what kind of software I want to build, but I may not know what kind of code to write to get there.
In data science, you deal with data unknown unknowns instead—I have no idea all what the data will show me and whether it is possible to do what I set out to do.
Imagine a person with perfect coding ability. Said person will have no problem complete any software project. But the same person still has to solve data issues in a data science project and may still need to change the goal because the data is not there.
Frustration from applying Scrum in data science
Now let’s go over why I believe it is difficult to run a Scrum team in data science:
- New insight (from data) changes priority and makes sprint goal useless.
Scrum works when a you can turn the roadmap of a project in a spec. The Scrum process then turns the spec into product. You can’t do that in data science.
Let me say it again: you can’t do that in data science.
In my experience with data science projects, what you set out to do often turns out to be impossible and there is nothing you can do but pivoting to a new goal.
Let’s say I’m in the middle of a two week sprint and I found that my sprint goal is impossible. What can I do?
Common sense says that I can ditch the sprint goal and meet with my team to set a new goal within the sprint, so we don’t waste another week of time.
But this means that I expect to have interruptions within the sprint. If the goal of sprints is to minimize interruption and boost productivity and I know interruptions are inevitable, why put a timebox in the first place?
Two workflows
Before I go into a solution, let me digress on the data science workflow.
In my post
I said that every data science project has two stages:
- an exploration stage, and
- a product stage.
The product stage is similar to a software development project. Here, Scrum woks. If you know what you need to build and can put the steps into a spec, then go ahead and run the sprints.
The exploration stage, however, is where data scientists dance with ambiguities. This is where running Scrum without context turns a project into a disaster.
Enters Kanban
- Reading about Kanban: https://www.atlassian.com/agile/kanban
What is Kanban?
Kanban is a task queue. A basic Kanban board has 3 parts:
- To-Do
- Doing (Work in Progress, or WIP.)
- Done
The key constraint in Kanban is a cap on how many tasks can be in WIP at the same time. If the limit is 3, then the team can work on 3 tasks at once and no more.
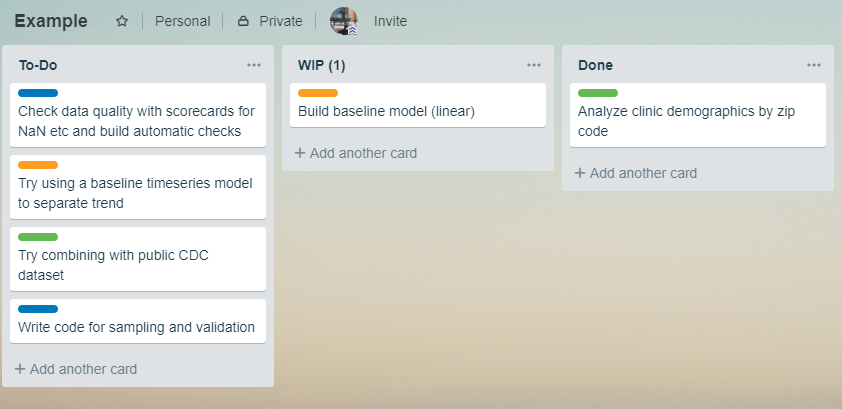
(In Scrum, the constraint is the time: sprints are timeboxes. Frameworks use constraints to limit the project complexity and scope and that’s why they work.)
In the To-Do queue, tasks are ranked by their priorities. When a task in WIP is finished, the team picks up the task on the top of To-Do.
You may ask, what happens when a card gets stuck in WIP indefinitely? This is a real problem. So, in Kanban, project manager tracks cycle time i.e. the time between starting and delivering the task, or in other words, how long did the card sits in WIP.
The team can set an agreement to review a card if any card was stuck in WIP for say, one week, then take action to resolve the issue.
How does Kanban help in exploration?
Let’s see how Kanban deals with the following problems which frustrates Scrum users the most:
- New insight changes priority and makes sprint goal useless.
In Kanban, managing the priority of tasks is the same as managing the order of cards in To-Do.
Therefore, when new priority arises, instead of having to call a meeting to make a new plan of who works on what, the project manager can change the order of cards and notify team with the reasons.
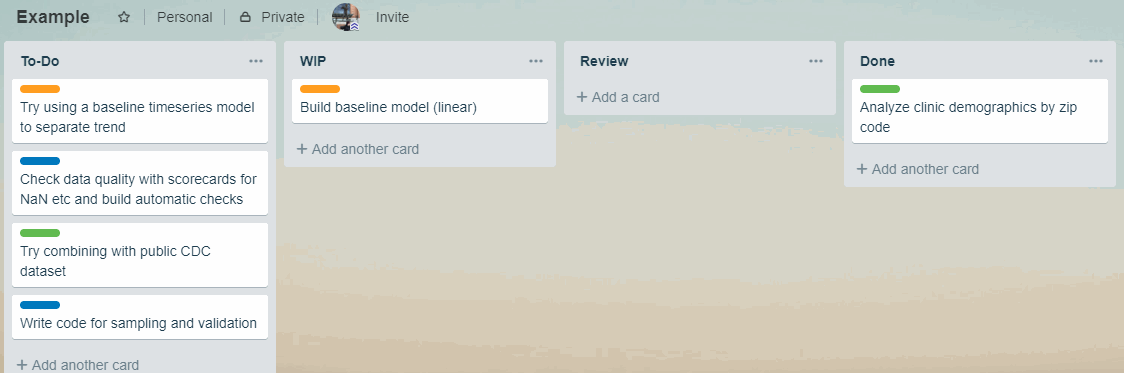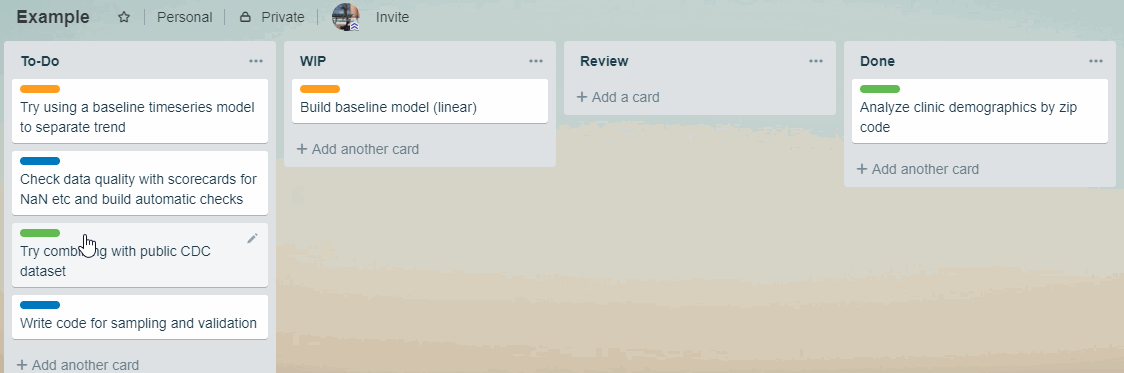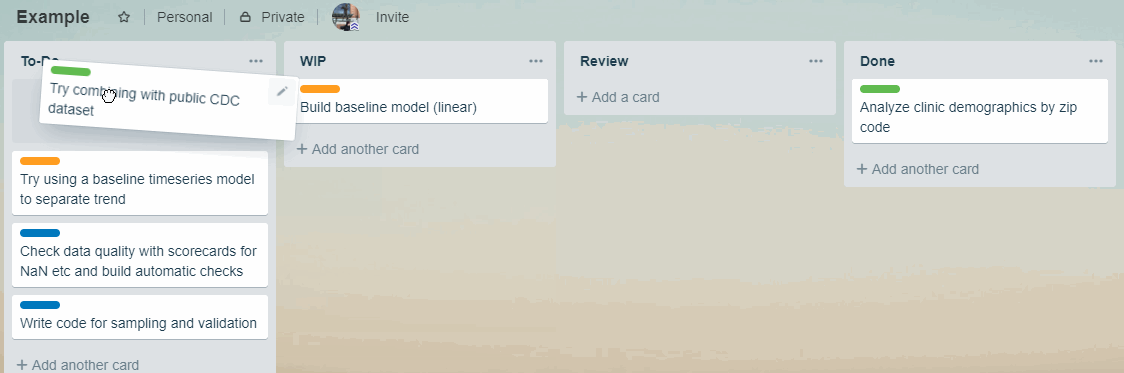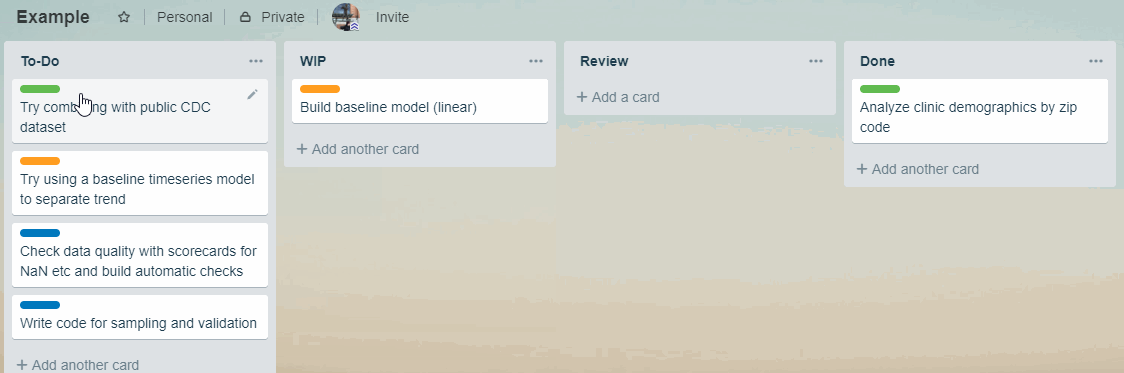
This means fewer interruptions and things get done.
This conclusion bears another question: if it is impossible to come up with a spec in the exploration stage. Then what does it mean to get things done in the exploration stage?
Instead of answering it directly, let me ask another question: what is a basic unit of work for data scientists when exploring?
I say the basic unit of work for exploration is experiment and the measure of productivity in exploration is the number of experiments.
Basic unit of data science work
Let’s review again:
- In software development, we can write specs and turn specs into tasks. The basic unit of work comes from the spec and can be put into a timebox.
- In data science, there is no spec in exploration. The basic unit of work is experiments that come from the hypotheses around data.
What do I mean by experiment?
Experiments answer queries.
There’s always question around data:
- how is data collected
- how is data
- did any of the above assumption changed at some point in my data
For example, if I have the healthcare data by zip code and my goal is to model diabetes patient care and I have a dataset that comes from CDC based on phone survey data, then I might want to ask:
- Is there a diabetes cluster somewhere in my city? Why?
Then I can dive into data and see if anything pops up that are related to my question. Depending on what I see, it may lead to another question: what’s the assumption around the phone survey? Can I trust the sampling? etc.
The goal of the project may be to build a model, but I can’t build a robust model without understanding the business and verifying my hypotheses around the datasets.
Run experiments, revise assumptions around data, then run another one.
Pop a experiment into To-Do, run it in WIP, document the findings, then push it to Done. This is a great workflow to help the team find the data traps and pitfalls in the process of building a robust model.
Takeaways
- Don’t use out-of-the-box Scrum. Throw away parts that makes no sense in data science and save yourself the frustrations.
- Kanban works better in the exploration phase.
- No matter which framework you pick, think about the assumptions around it—Scrum works under a set of assumptions and so does Kanban. Take the practices that work well in your context.
Questions that I have not answered
Another question came up from this discussion: if there are two workflows in data science, how can I balance my time or my team’s time between the workflow? Is there a general principle that I can follow?
Let’s think through this question later.
Appendix: a Kanban board example
I don’t see anyone put their data science Kanban board in public, but here’s one from software development:
Subnautica is one of my favorite video game of all time and they let everyone track their development progress on a public Kanban board:
https://trello.com/b/yxoJrFgP/subnautica-development